Blog & Demos
Tutorials, case studies, benchmarks, and open-source demos — everything you need to build with small language models.
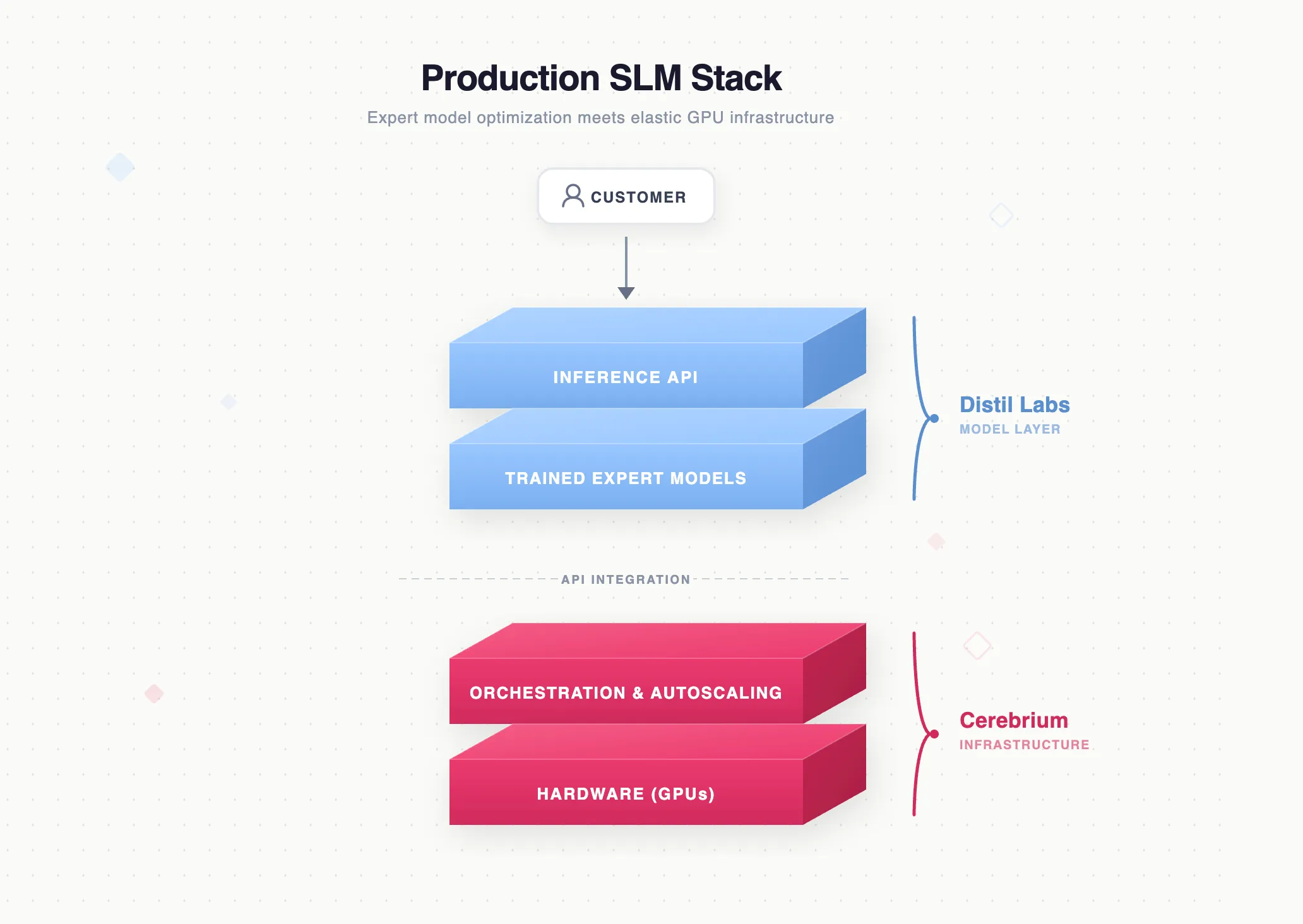
Full-Stack Production Language Models: Expert Model Optimization Meets Scalable GPU Infrastructure
How distil labs and Cerebrium combine expert model optimization with serverless GPU infrastructure to deliver an end-to-end stack for replacing expensive LLM inference with lean, production-grade small-model deployments.
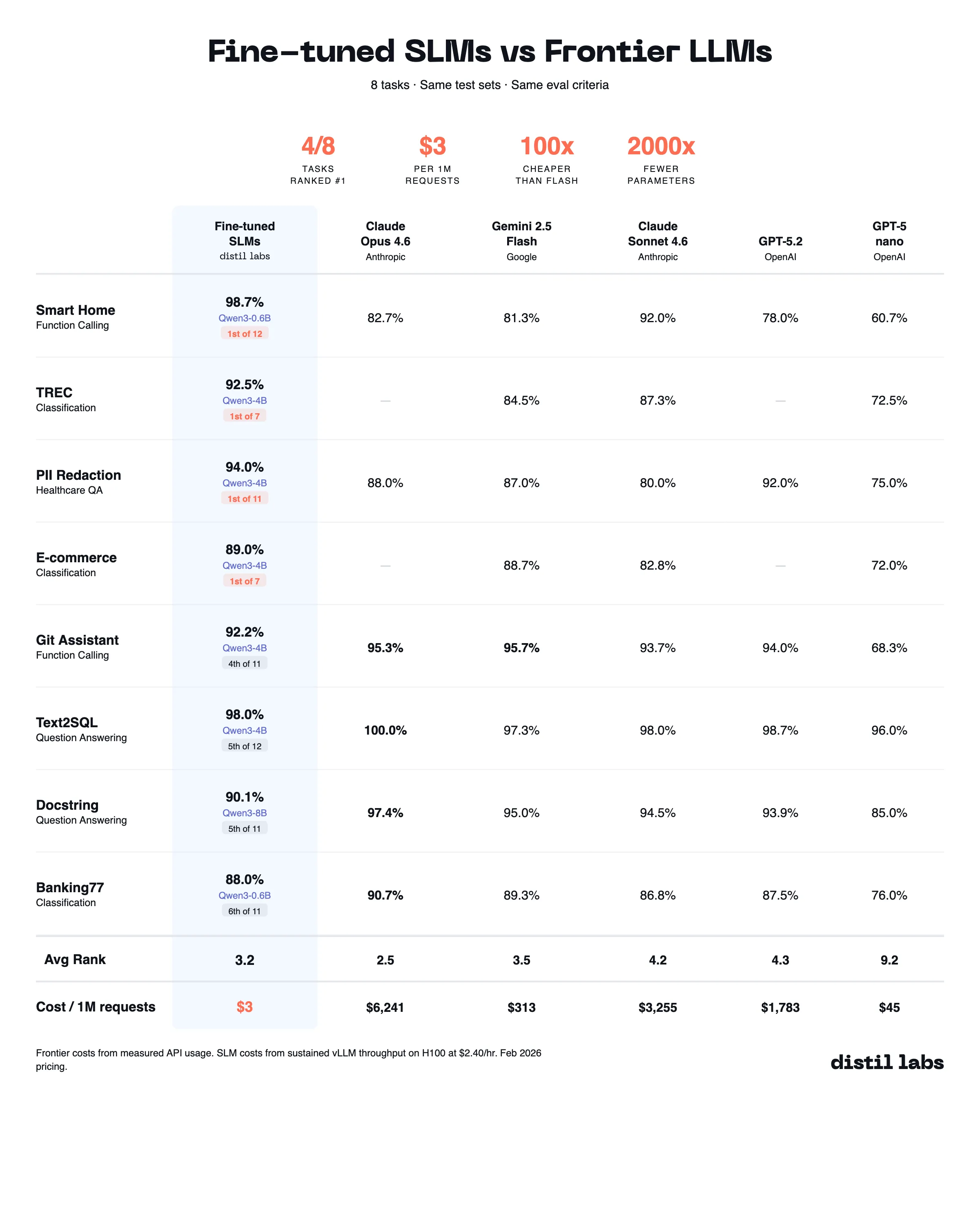
The 10x Inference Tax You Don't Have to Pay
Benchmarking fine-tuned small language models (0.6B-8B) against 10 frontier LLMs across 8 datasets shows that task-specific SLMs match or beat frontier models at 10-100x lower inference cost.

How Knowunity used distil labs to cut their LLM bill by 68%
Knowunity, an edtech startup processing hundreds of millions of AI requests monthly, used distil labs to train a custom small language model that cut inference costs by 68% while improving classification accuracy from 81% to 93%.
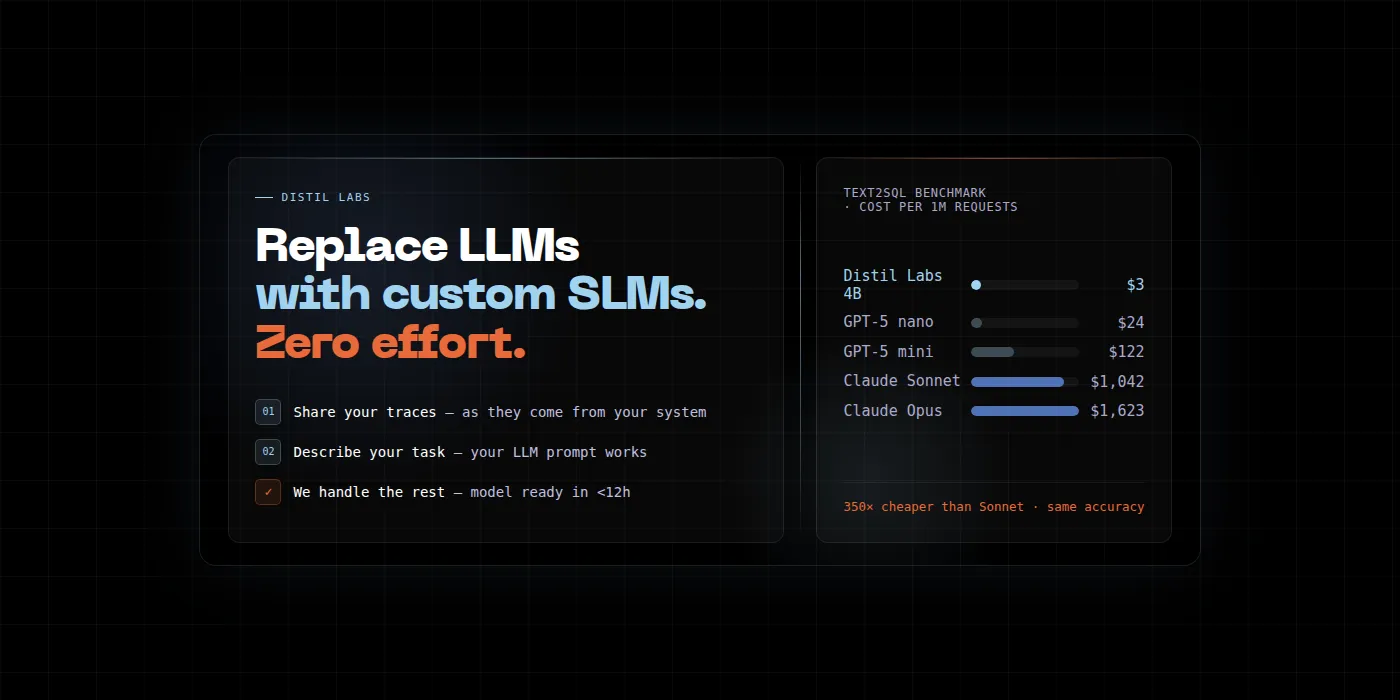
From Production Traces to a Faster, Cheaper, Accurate Model
Learn how to turn your production LLM agent traces into a compact specialist model that outperforms the original, with zero manual annotation and deployment in under 12 hours.
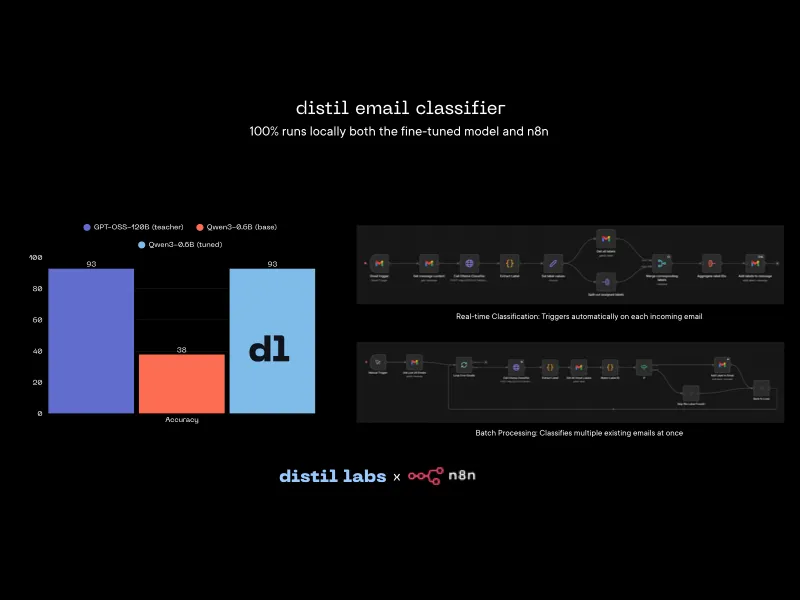
How to label your emails locally with a distil labs fine-tuned model and n8n
Build a fully local Gmail email classification pipeline using a distil labs fine-tuned 0.6B model and n8n, keeping all email data private on your machine.
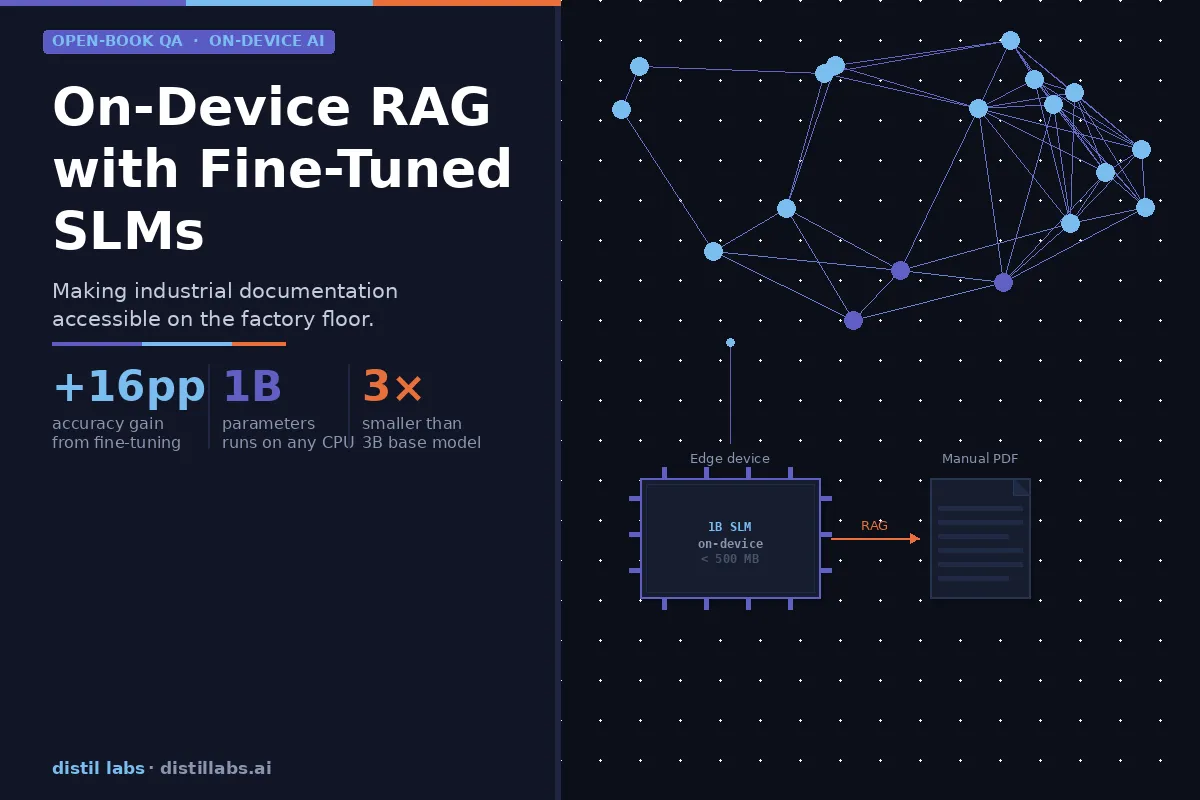
How SLMs Can Enable On-Device RAG - Making Industrial Machinery More Usable
Fine-tuned 1B parameter models can match the accuracy of 3B base models on domain-specific documentation — making on-device RAG viable for industrial equipment without expensive AI-optimized hardware. We tested this on a Siemens PLC manual and achieved a +16 percentage point accuracy gain through distillation.

Making FunctionGemma Work: Multi-Turn Tool Calling at 270M Parameters
Google's FunctionGemma scores just 10-39% on multi-turn tool calling out of the box, but after fine-tuning with distil labs it reaches 90-97% accuracy across three benchmarks, matching or exceeding a 120B teacher model at 270M parameters.
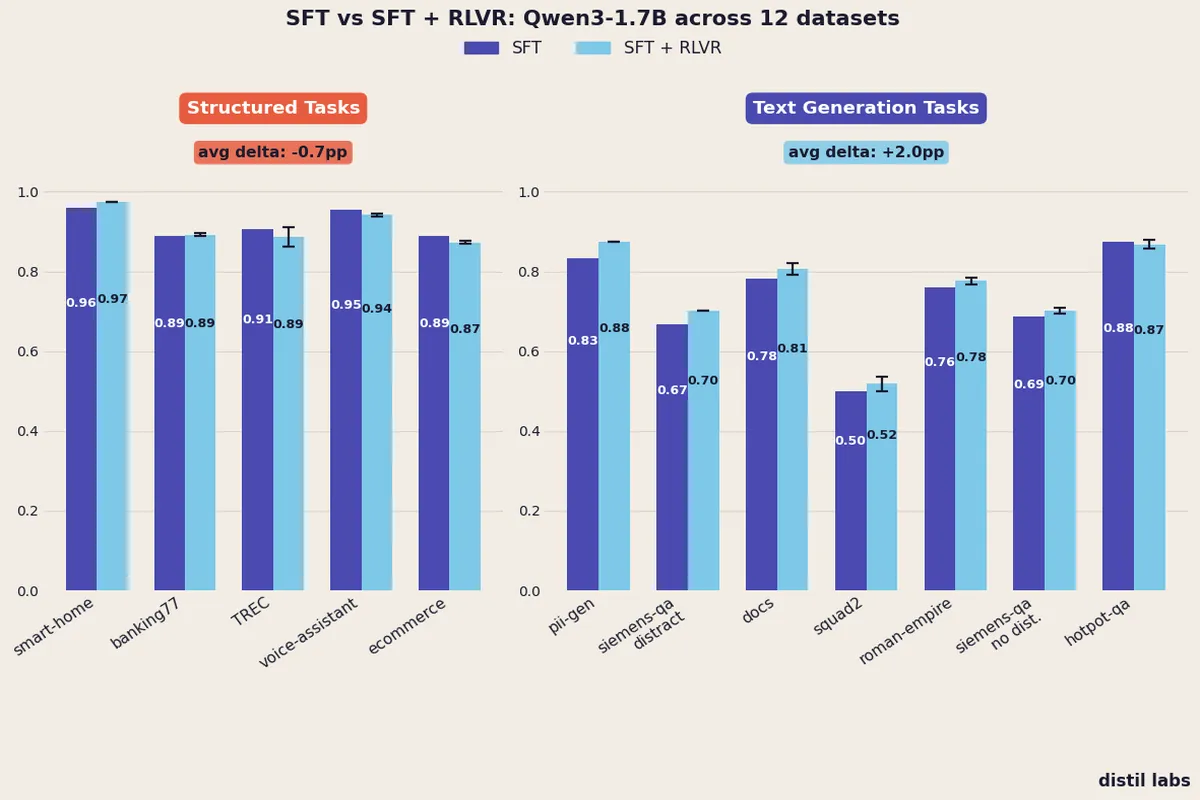
When Does Reinforcement Learning Help Small Language Models?
A controlled experiment across 12 datasets reveals that adding RLVR after SFT consistently improves text generation tasks (+2.0pp) but provides no reliable benefit for structured tasks like classification and function calling.
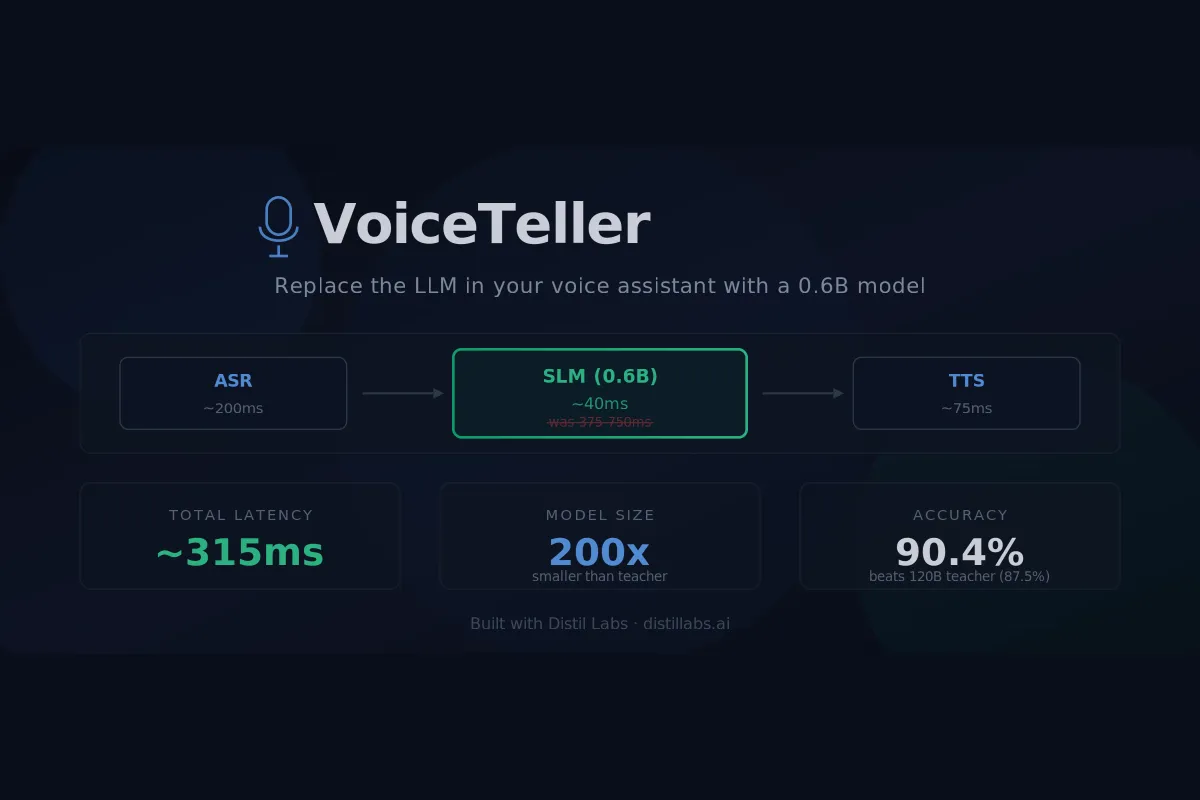
The LLM in Your Voice Assistant Is the Latency Bottleneck. Replace It with an SLM.
Voice assistants on cloud LLMs are slow and expensive per turn. A fine-tuned SLM is cheaper and faster per request with equal-or-better accuracy on bounded tasks: brain-stage latency drops from ~700ms to ~40ms, and per-turn cost from cloud-API rates to server-amortized pennies.