Benchmarks
Data-driven performance comparisons for small language models fine-tuned with distil labs.
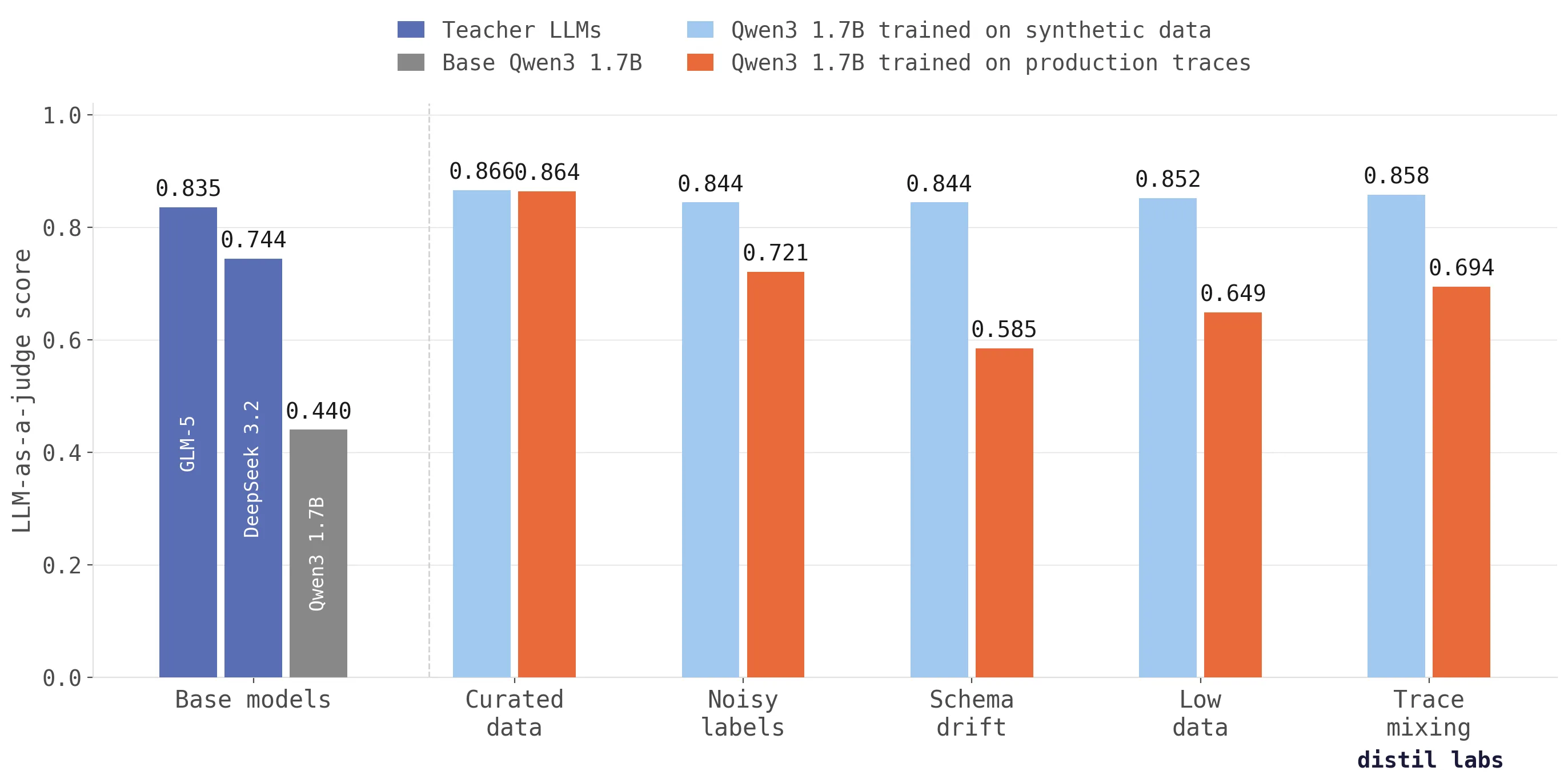
Why training on production traces fails (and what to do instead)
Training directly on production traces doesn't work as well as you'd expect. We tested across five scenarios and synthetic data from traces scores up to 26 percentage points higher in accuracy.
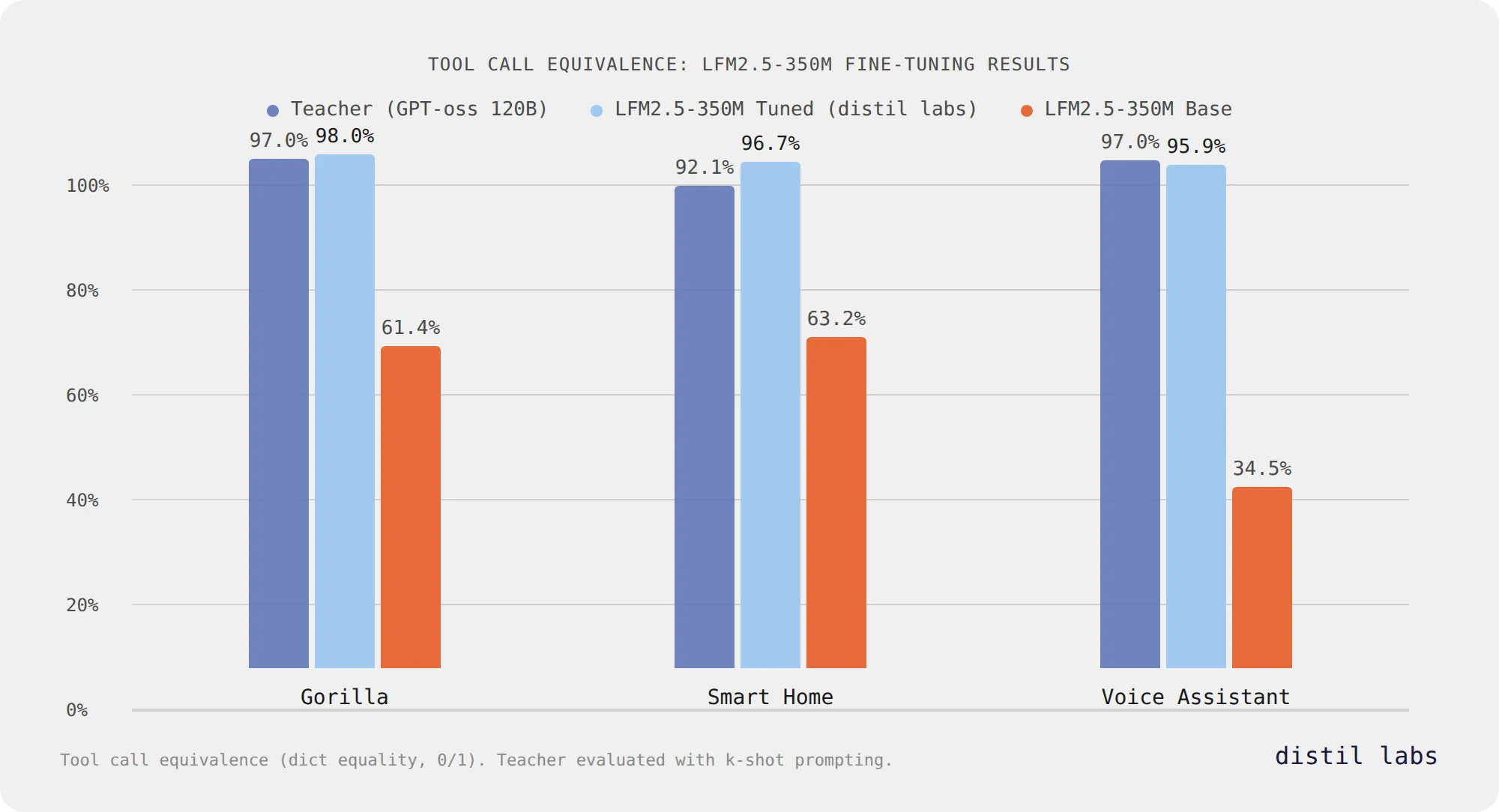
Fine-Tuning Liquid's LFM2.5: Accurate Tool Calling at 350M Parameters
Liquid AI's LFM2.5-350M reaches 96-98% tool call equivalence after fine-tuning with distil labs across three benchmarks, matching or exceeding a 120B teacher model while staying at 350M parameters.
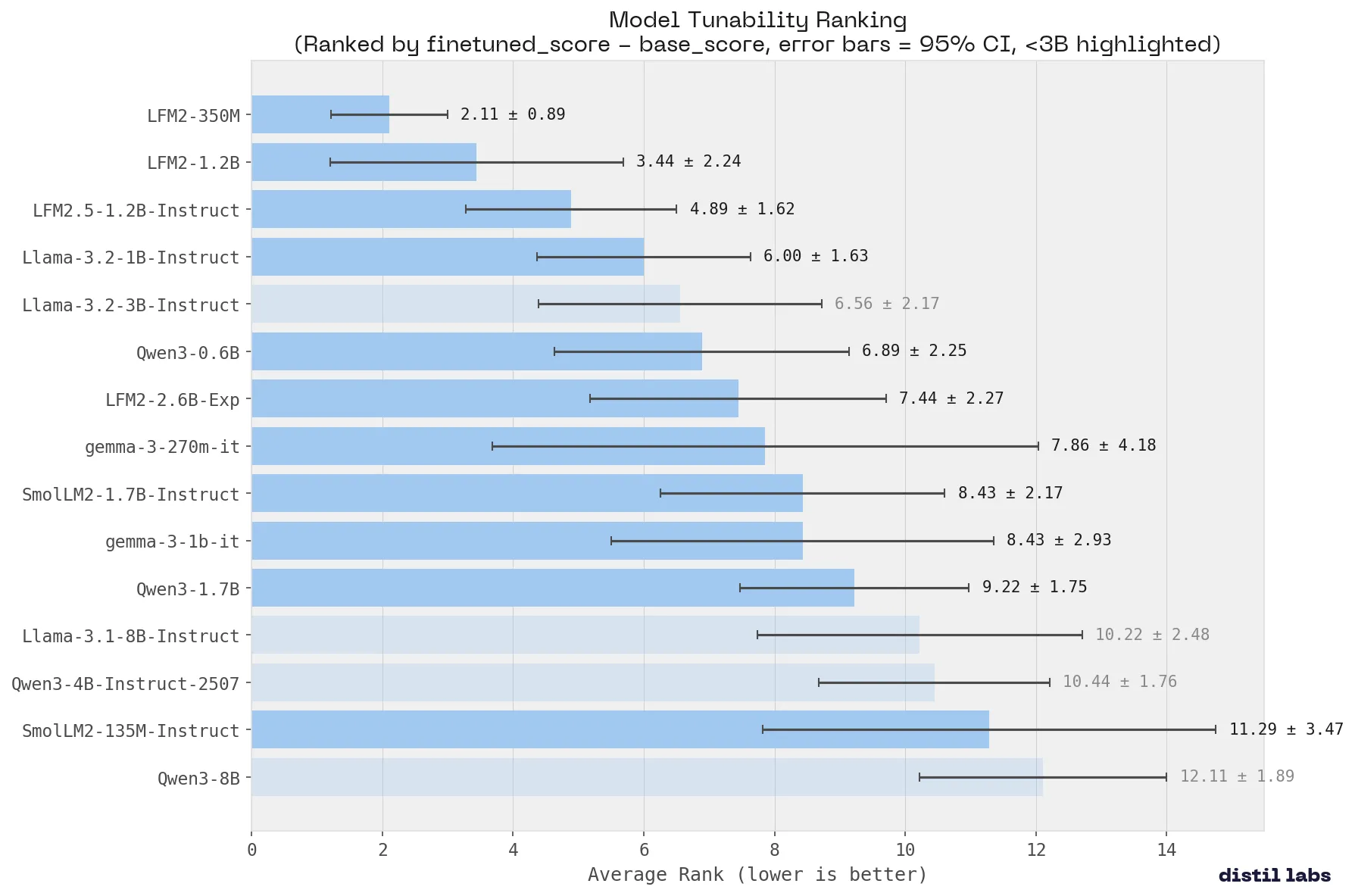
What Small Language Model Is Best for Fine-Tuning
We benchmarked 15 small language models across 9 tasks to find the best base model for fine-tuning. Qwen3-8B ranks #1 overall. Liquid AI's LFM2 family is the most tunable. Fine-tuned Qwen3-4B matches a 120B+ teacher on 8 of 9 benchmarks.
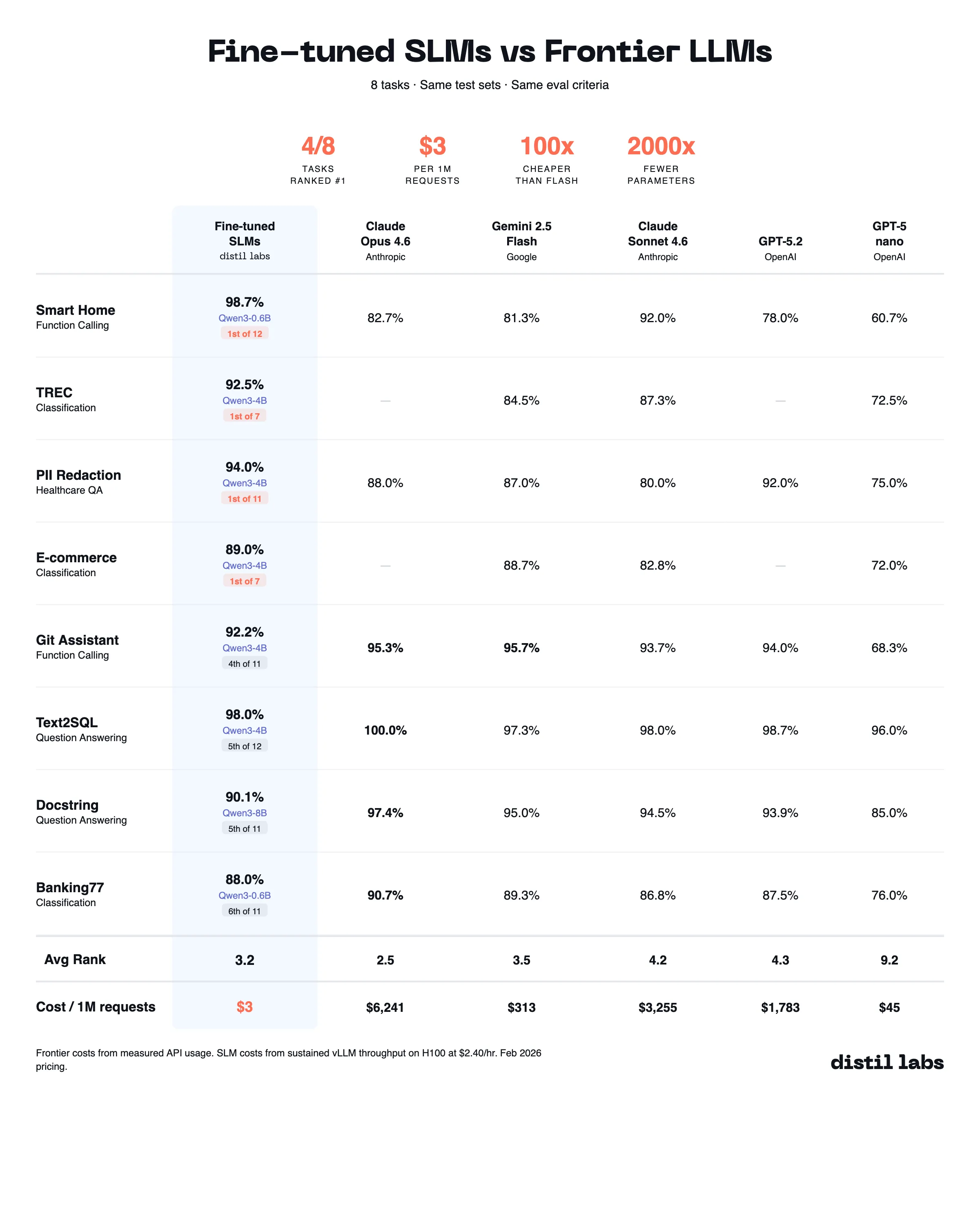
The 10x Inference Tax You Don't Have to Pay
Benchmarking fine-tuned small language models (0.6B-8B) against 10 frontier LLMs across 8 datasets shows that task-specific SLMs match or beat frontier models at 10-100x lower inference cost.
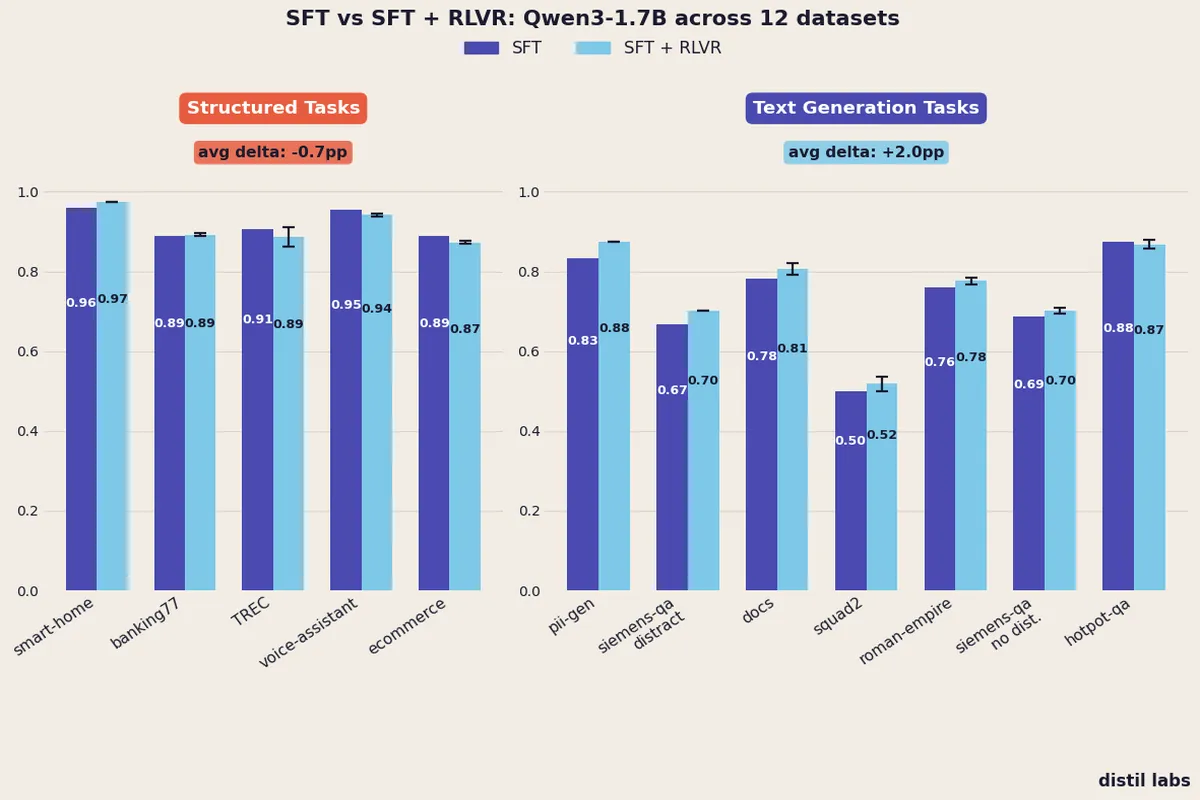
When Does Reinforcement Learning Help Small Language Models?
A controlled experiment across 12 datasets reveals that adding RLVR after SFT consistently improves text generation tasks (+2.0pp) but provides no reliable benefit for structured tasks like classification and function calling.
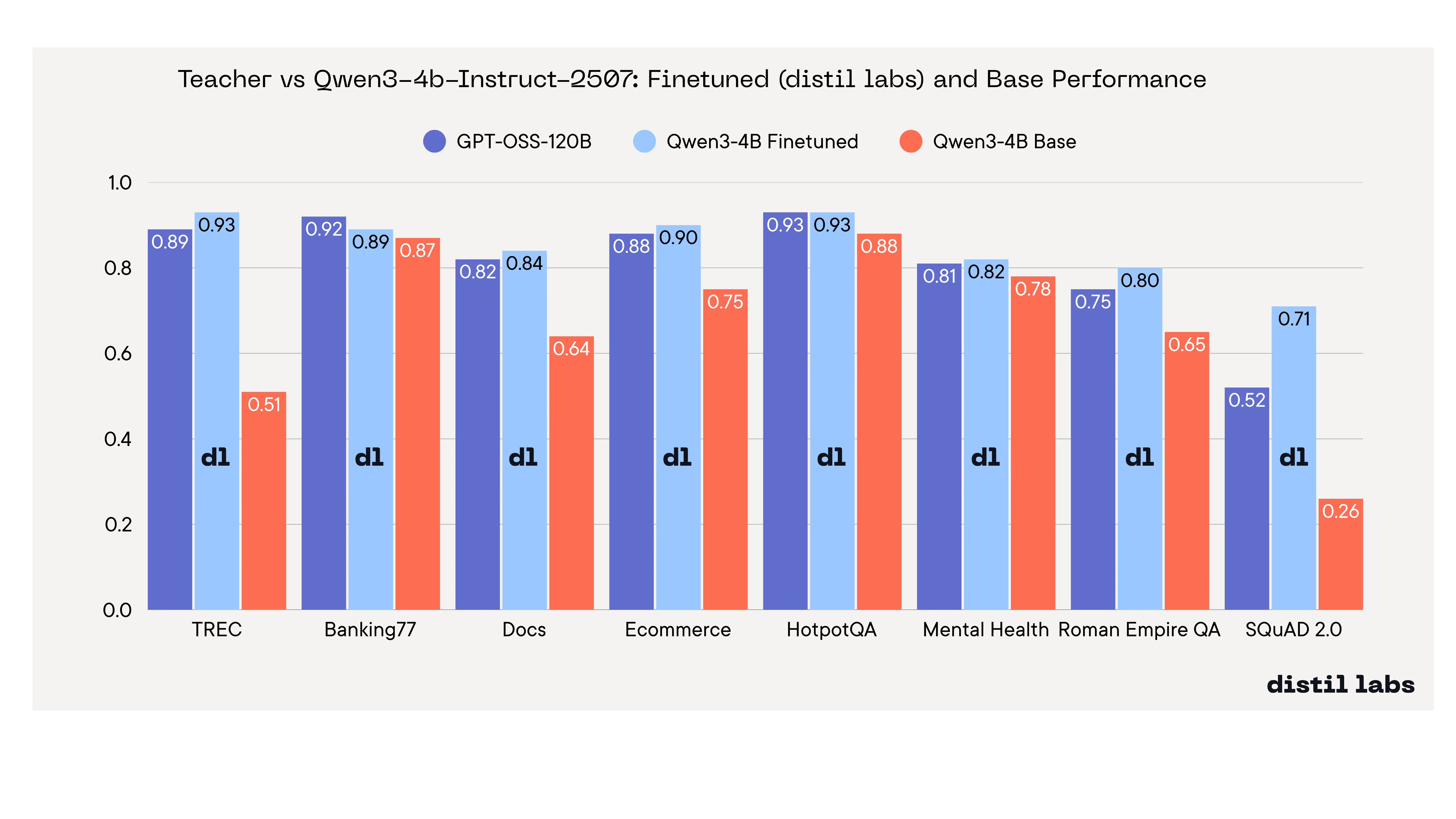
We Benchmarked 12 Small Language Models Across 8 Tasks to Find the Best Base Model for Fine-Tuning
A systematic benchmark of 12 small language models across 8 tasks reveals Qwen3-4B as the best for fine-tuning, with fine-tuned models matching or exceeding a 120B+ teacher. Smaller models like Llama-3.2-1B show the highest tunability.
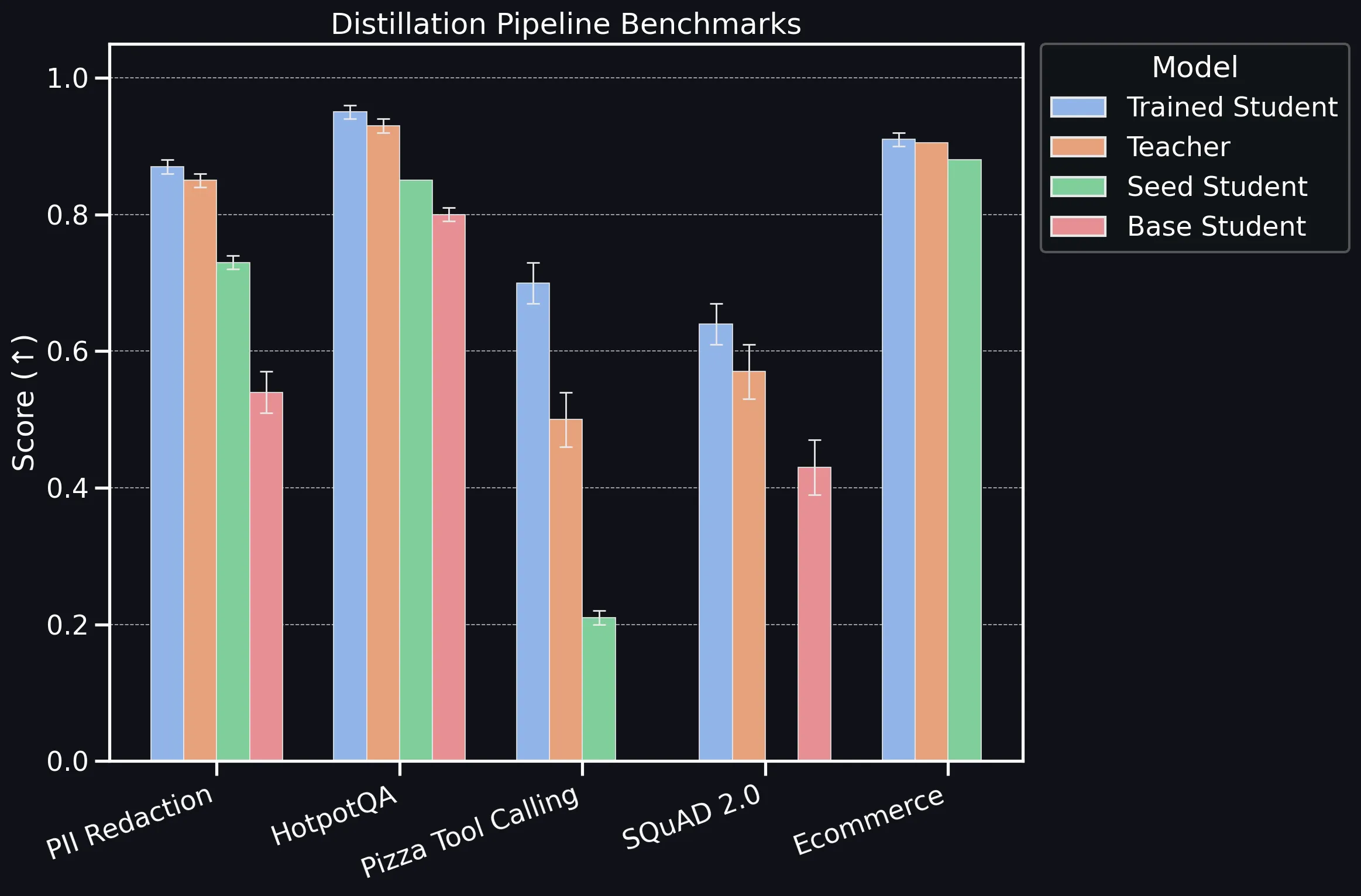
distil labs: Benchmarking the Platform
Benchmarking distil labs' distillation pipeline across classification, information extraction, QA, and tool-calling tasks, showing that compact SLMs consistently match or exceed teacher LLMs.