Guides
How-tos and strategic perspectives on building with small language models.
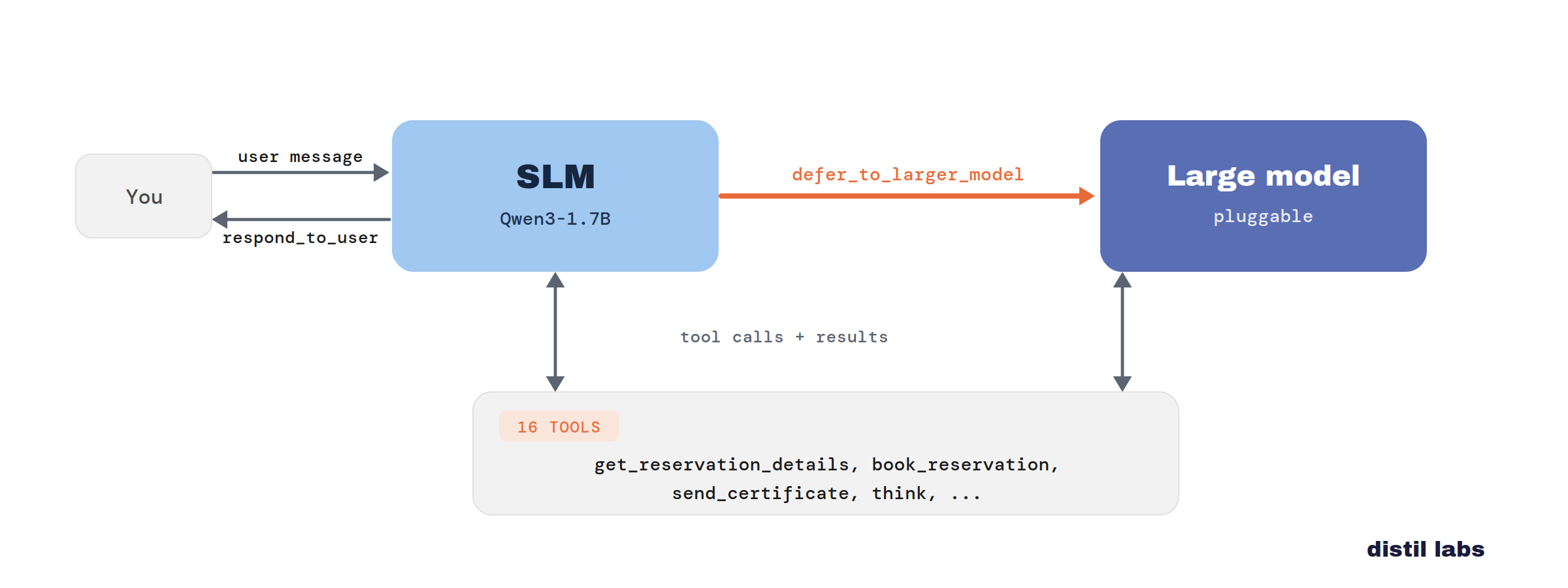
Don't Build a Router. Train the Small Model to Know When to Defer.
A fine-tuned small model handles the easy majority of customer-support turns and defers the genuinely-hard minority to a frontier model — matching all-frontier quality at a fraction of the cost. No router, no thresholds, no second classifier: the small model is trained to recognize when it's out of its depth and escalate with a single tool call.

Distil PII Redactor: an OpenClaw Skill
Locally redact PII from text using a fine-tuned 1B parameter model packaged as an OpenClaw skill. Your sensitive data never leaves your machine.

Train an SLM from your production traces with the distil labs Claude skill
A walkthrough of using the distil labs Claude skill to turn 327 noisy production traces into a fine-tuned Qwen3-1.7B multi-turn tool-calling model, deployed on a managed endpoint in a single conversation.
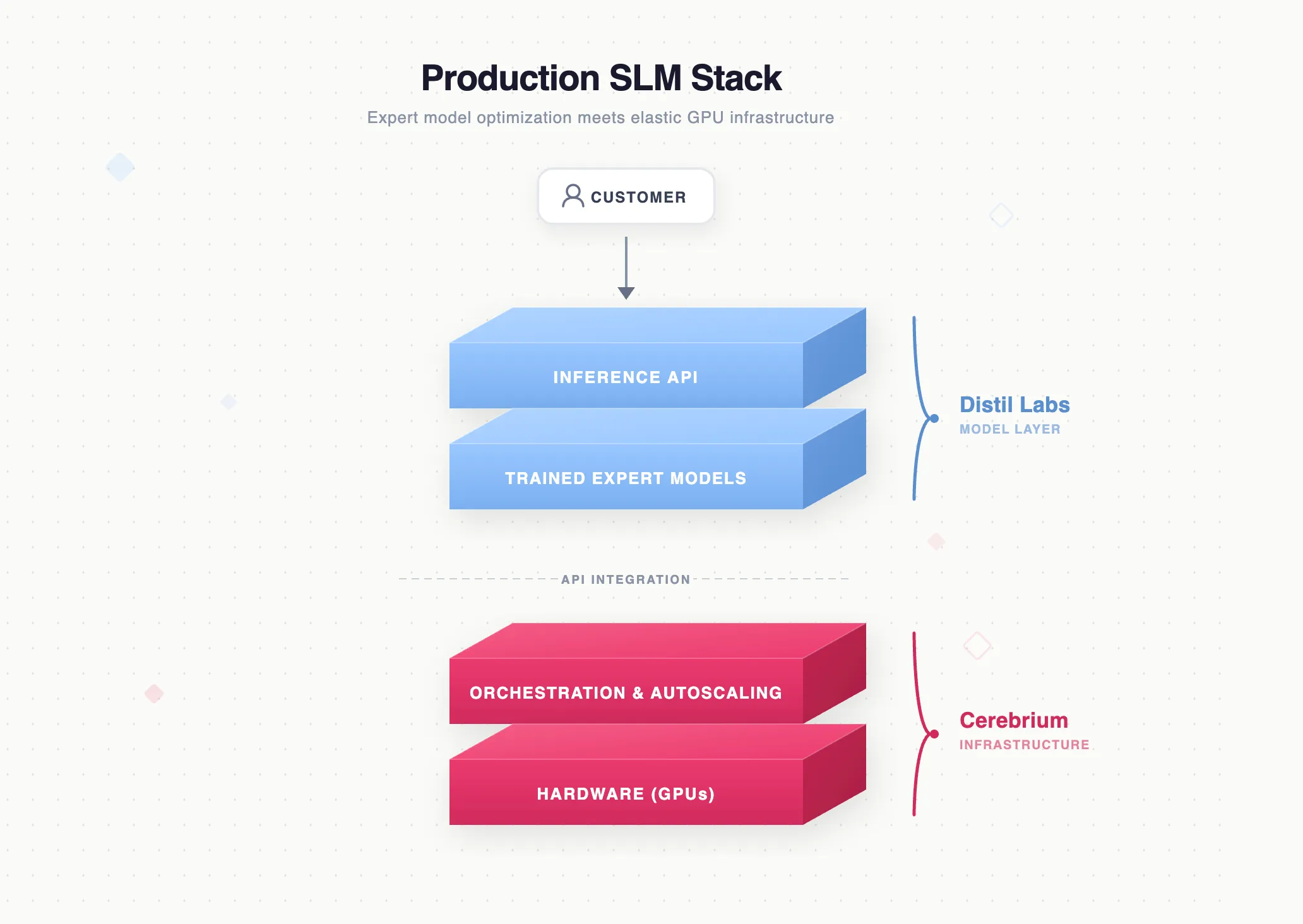
Full-Stack Production Language Models: Expert Model Optimization Meets Scalable GPU Infrastructure
How distil labs and Cerebrium combine expert model optimization with serverless GPU infrastructure to deliver an end-to-end stack for replacing expensive LLM inference with lean, production-grade small-model deployments.
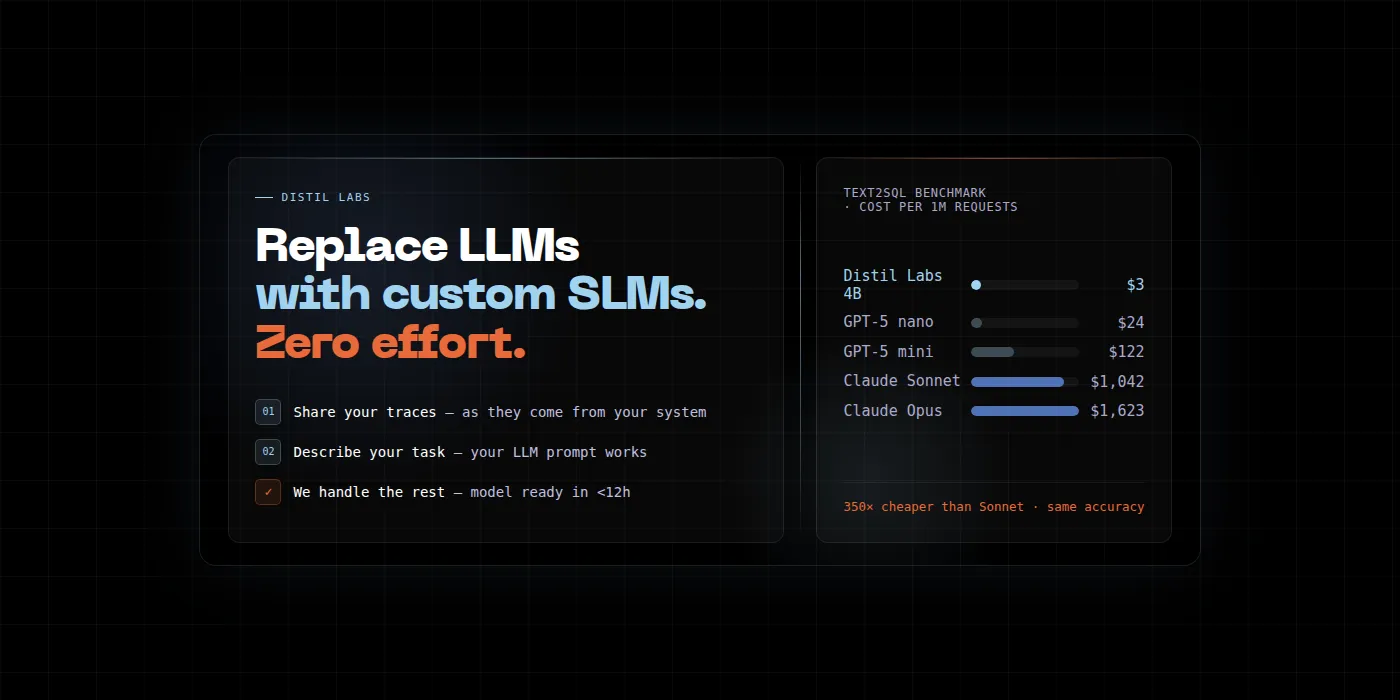
From Production Traces to a Faster, Cheaper, Accurate Model
Learn how to turn your production LLM agent traces into a compact specialist model that outperforms the original, with zero manual annotation and deployment in under 12 hours.
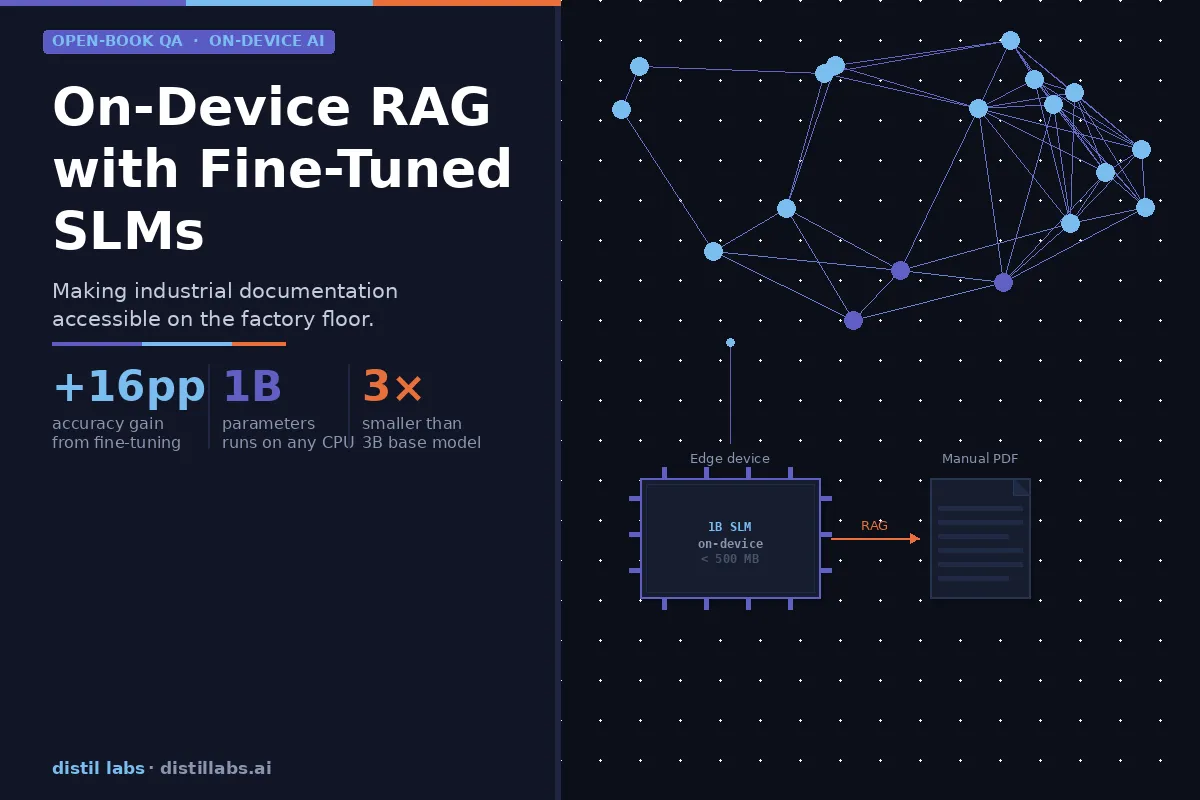
How SLMs Can Enable On-Device RAG - Making Industrial Machinery More Usable
Fine-tuned 1B parameter models can match the accuracy of 3B base models on domain-specific documentation — making on-device RAG viable for industrial equipment without expensive AI-optimized hardware. We tested this on a Siemens PLC manual and achieved a +16 percentage point accuracy gain through distillation.
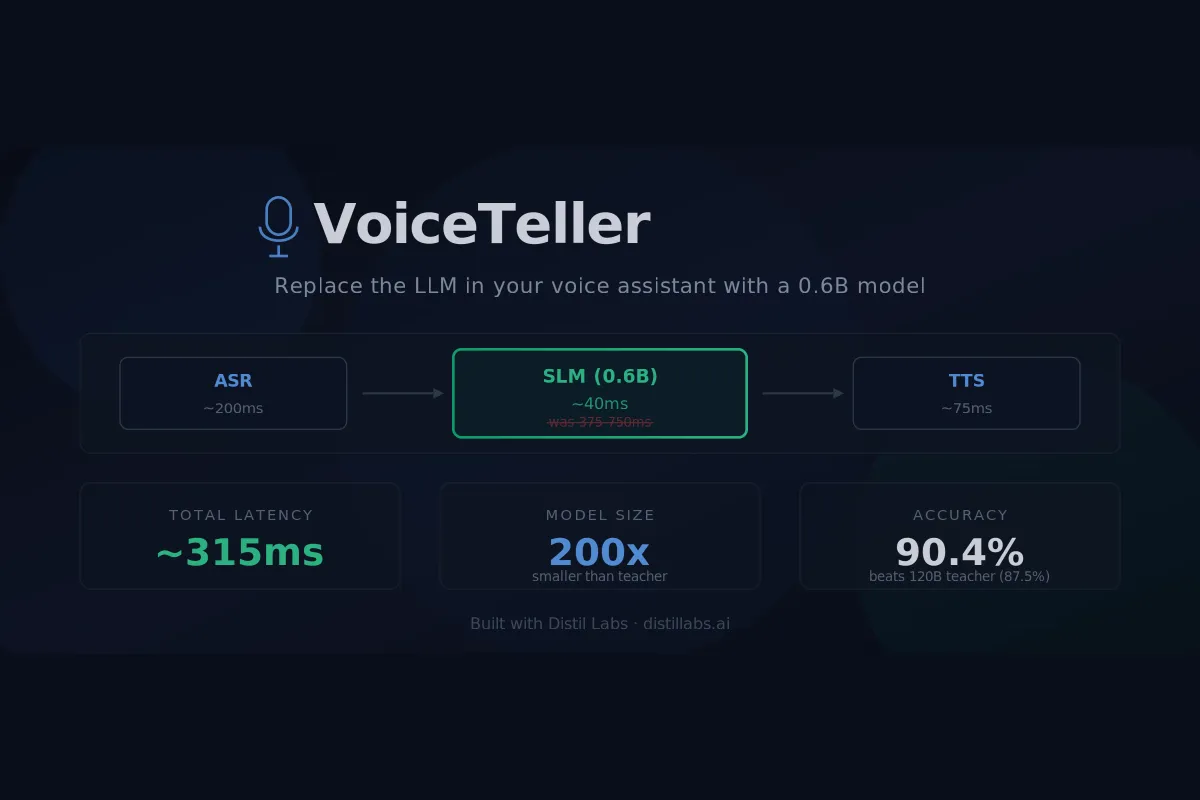
The LLM in Your Voice Assistant Is the Latency Bottleneck. Replace It with an SLM.
Voice assistants on cloud LLMs are slow and expensive per turn. A fine-tuned SLM is cheaper and faster per request with equal-or-better accuracy on bounded tasks: brain-stage latency drops from ~700ms to ~40ms, and per-turn cost from cloud-API rates to server-amortized pennies.
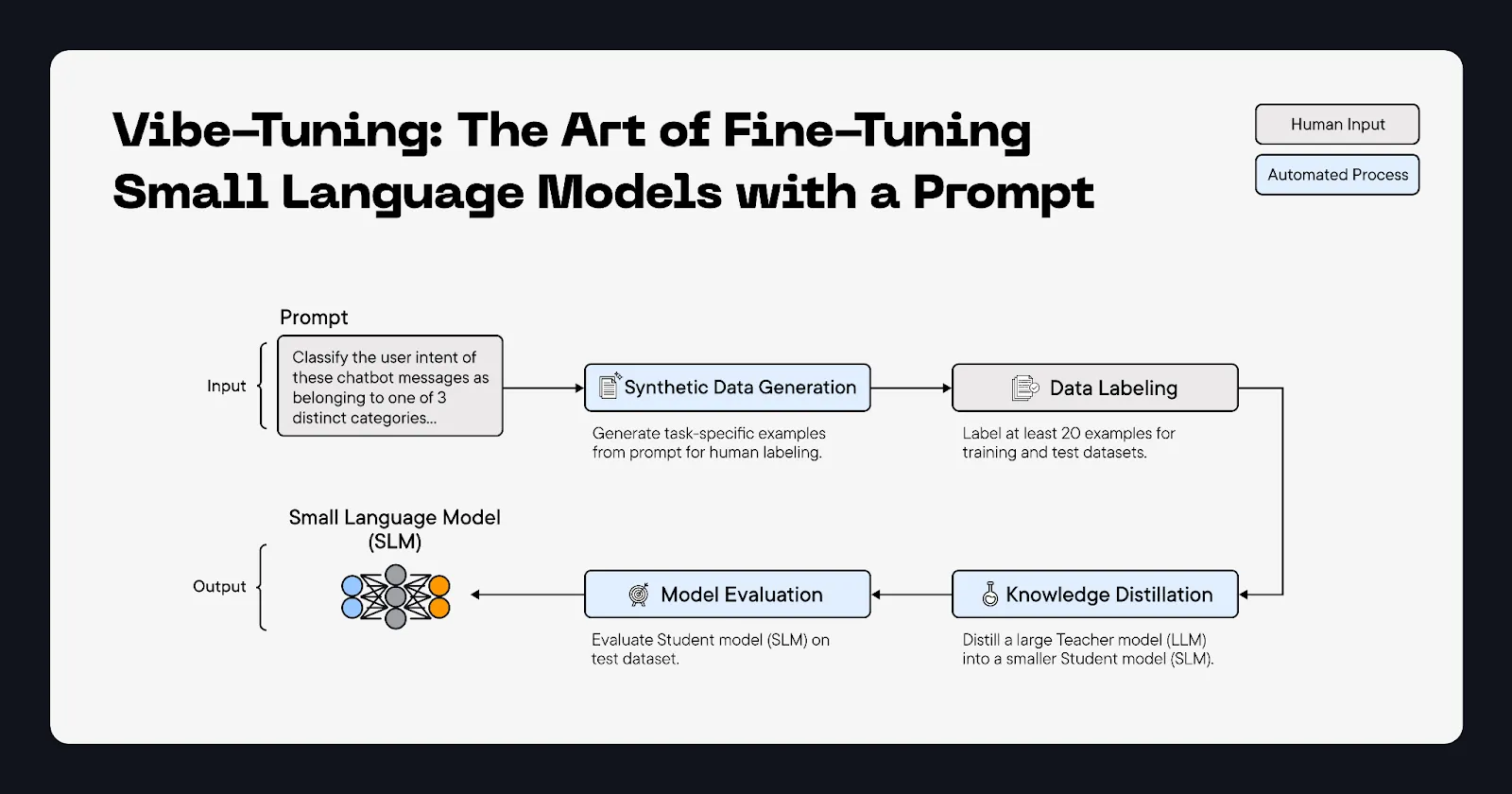
Vibe-Tuning: The Art of Fine-Tuning Small Language Models with a Prompt
Fine-tuning is a pain – you need datasets, ML expertise, and a stack of GPUs just to get started. Not anymore. With model vibe-tuning, you go from prompt to production-ready model without these headaches. This blog post shows you exactly how to build one, starting with just a prompt.
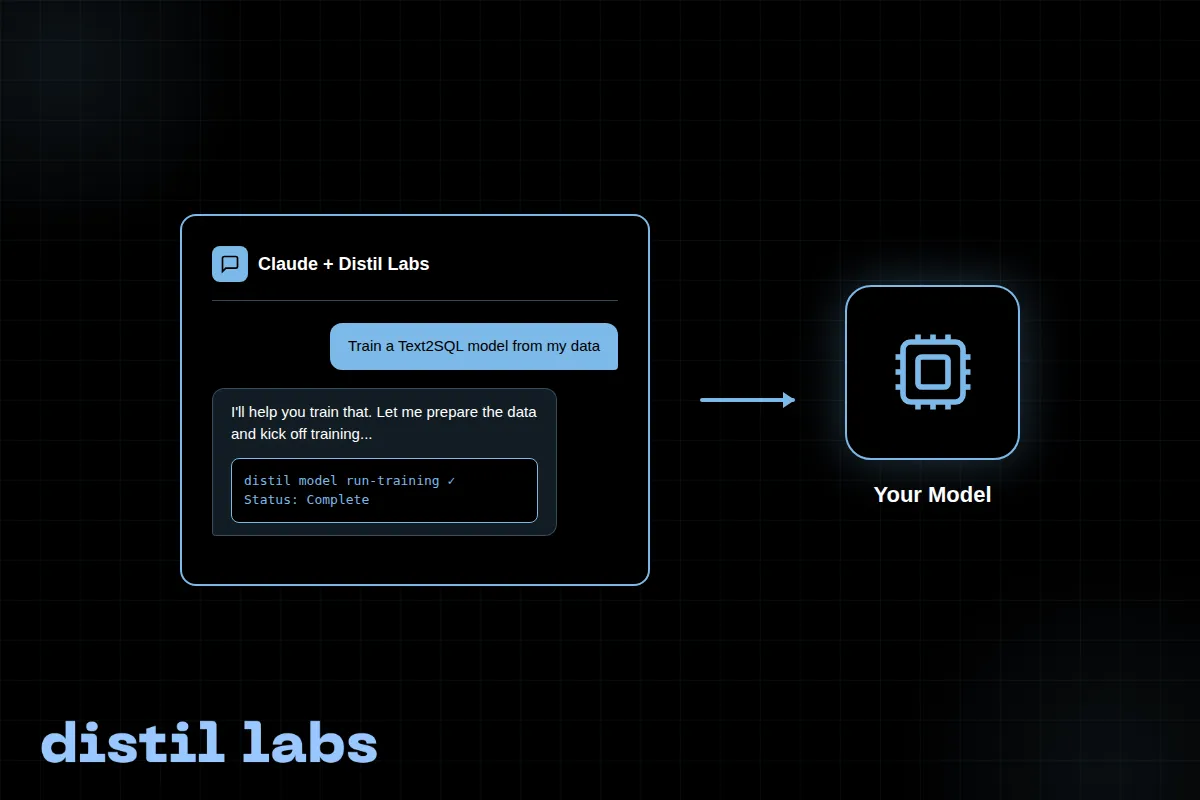
Train Your SLM with the distil labs Claude Skill
A step-by-step walkthrough of training a Text2SQL small language model using the distil labs Claude Code skill, going from raw conversation data to a working local model in a single conversation.