Train custom small language models with just a prompt
Developer platform for building task-specific SLMs with LLM-level accuracy in hours. Powered by knowledge distillation.







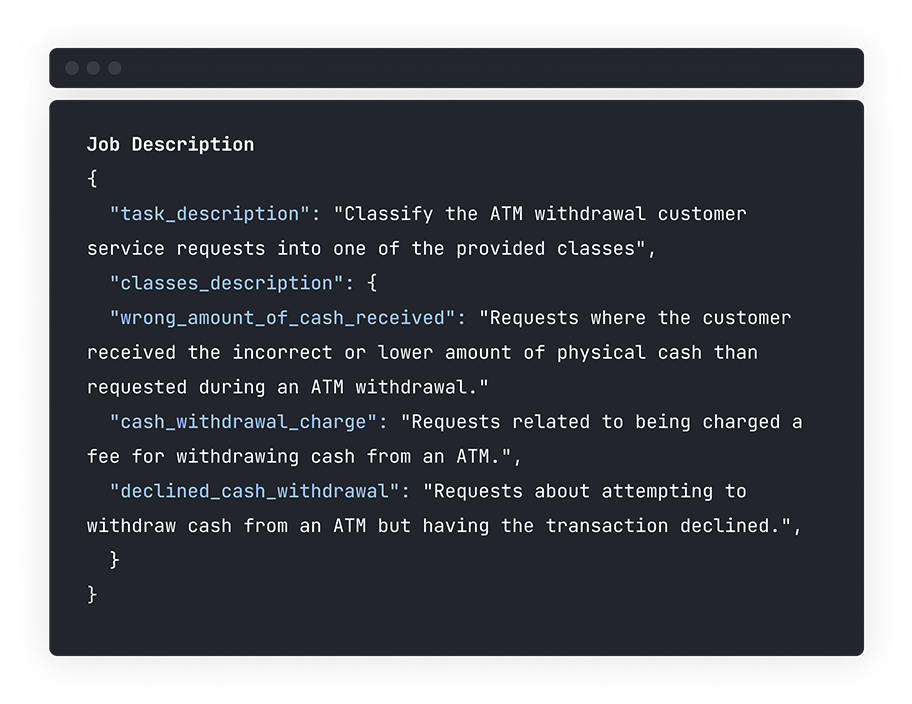
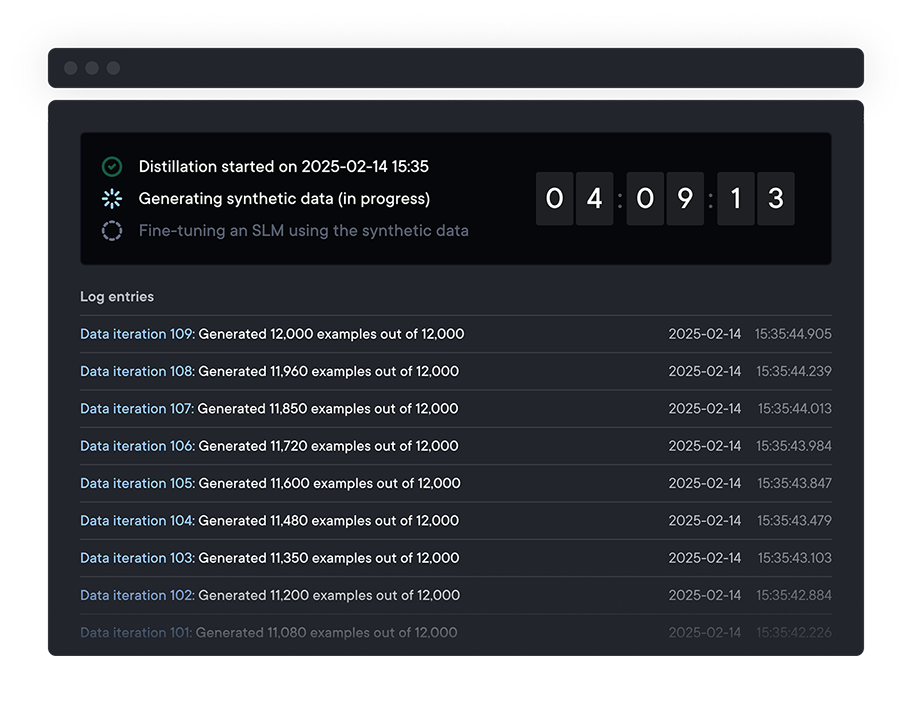





.svg)
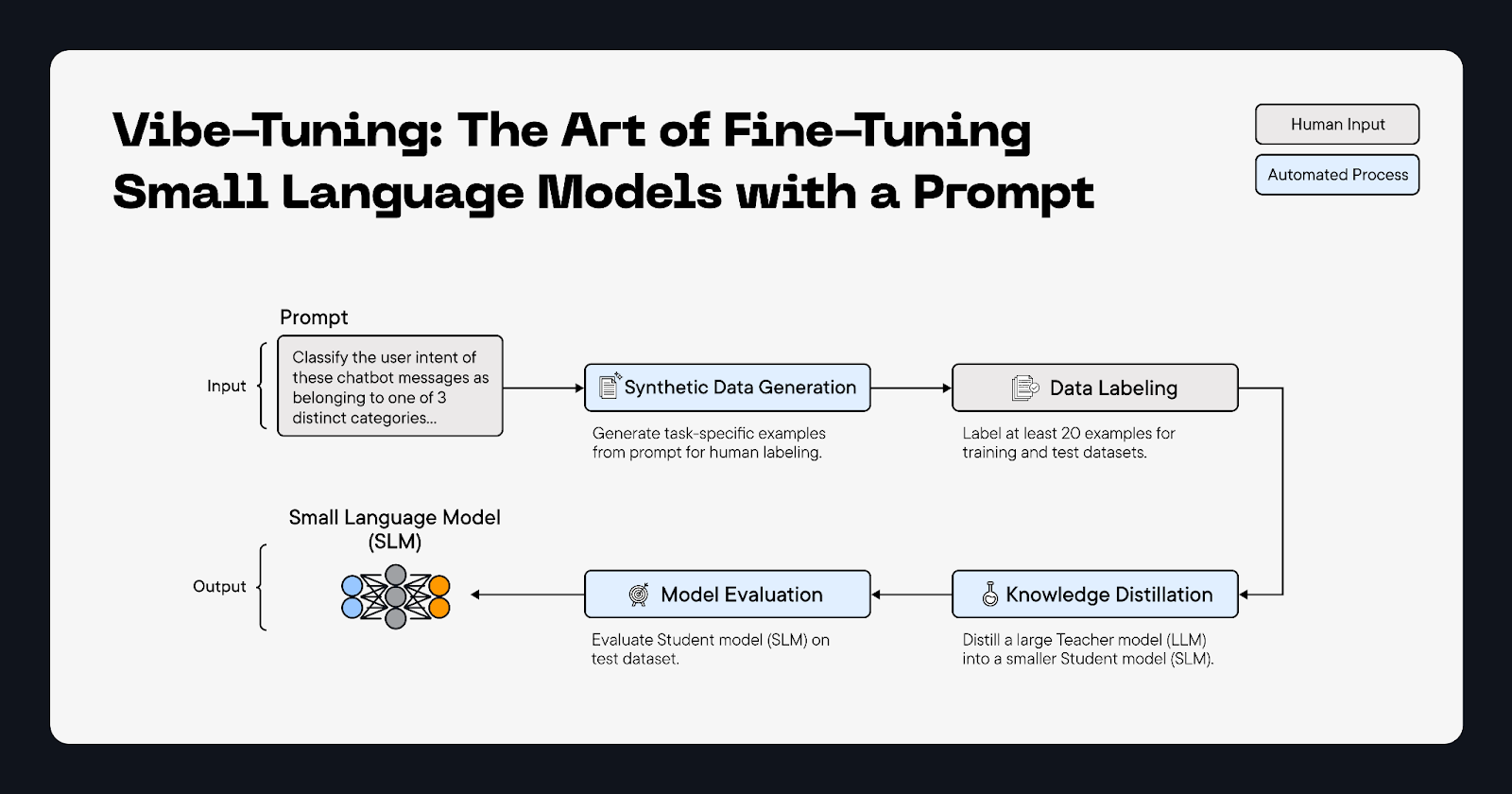
The more examples the better but we usually recommend using 10-50 diverse examples as the train set so your model can perform well on a variety of inputs.
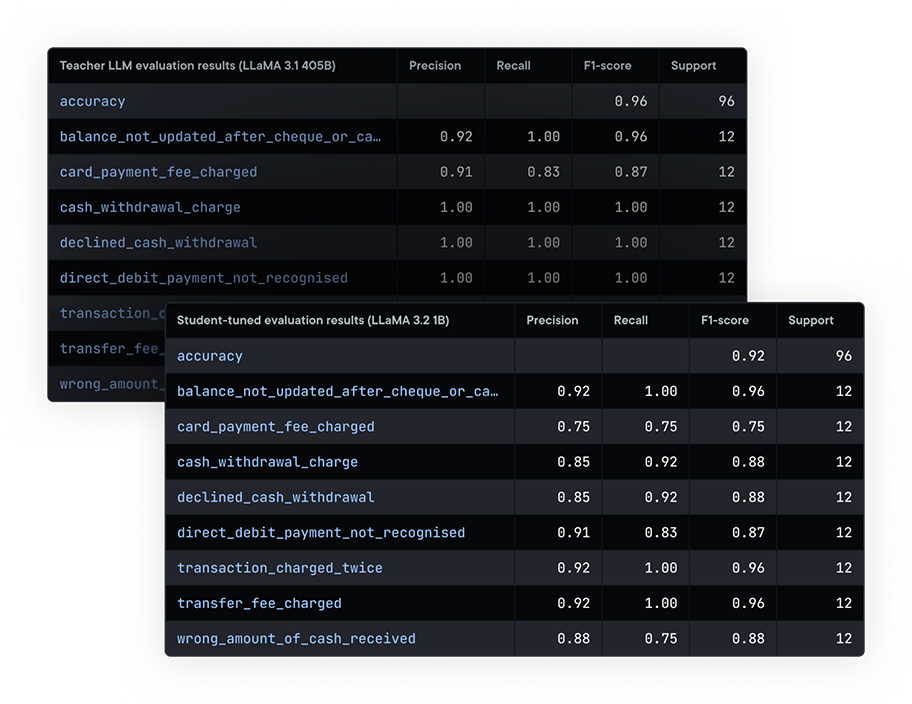
We aim for the trained models to have equal or higher accuracy than modern large language models such as Llama405b, GPT4, or else.
We can train any transformer-based models. We focus on SLMs between 100M and 8B parameters.
We support the most common NLP use cases such as Classification, Named Entity Recognition, extractive QA, function calling and ranking. Reach out to us or book a demo to learn more and let us know if you would like us to expand to new use cases.
We can either share the model binaries with you, so you can host it anywhere or host the model for you on our infrastructure.
Your data is encrypted on our servers and then removed after the model is trained.
.png)
.png)
.png)
